Attention & Transformers
What do we do if a sequence to sequence model needs to process a long sequence? As the sentance length increases, the output quality gets worse.
1. Attention
In a sequence to sequence model, the decoder is defined as
Where:
is the RNN hidden state of the decoder at step . is the RNN encoder feature output at step . is the alignment model, scoring similarity between the decoder state and the encoder output.
This is the attention mechanism, which allows the decoder to focus on different parts of the input sequence at each decoding step. The attention weights
2. Transformers
However, attention still relies on RNNs, which can be slow to train and may struggle with long-range dependencies.
2.1 Single Head Attention
Single Head Attention is defined as:
Where:
has query inputs of dimension . has key vectors of dimension . has value vectors of dimension . is a row-wise applied activation function.
Additionally:
- In self-attention,
. - In hard-attention
. Essentially, hard attention selects the single most relevant key for each query, resulting in a sparse attention distribution. - In soft-attention
. Soft attention produces a dense attention distribution, allowing the model to attend to multiple keys simultaneously, which can capture more complex relationships in the data.
Masked Attention is a variant of attention used in the decoder of the Transformer architecture to prevent the model from attending to future positions in the input sequence during training. This is achieved by applying a mask to the attention scores, ensuring that each position can only attend to previous positions and itself:
The masking matrix
The time complexity is
2.2 Multi-Head Attention
Multi-Head Attention allows the model to jointly attend to information from different representation subspaces at different positions. It is defined as:
Where
Now, the time complexity is
2.3 Transformer Architecture
We want to first use the attention based encoder to extract features from the input sequence, and perform the autoregressive decoding with the attention based decoder.
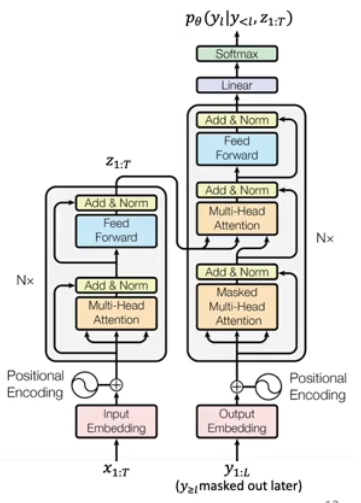
Positional Encoding injects ordering information into the input embeddings, since the attention mechanism itself is permutation invariant. A popular approach is
Add & Normalize layers are used to stabilize training and improve convergence. Layer Normalization is similar to batch normalization except it is performed within a single hidden layer output. The output is